Twitterの検索結果の1日単位のフィードを作った
Twitterの検索結果の1日単位のAtomフィードを作りました:
Twitter daily search result Atom feed
今までTwitter公式の検索結果フィードをGoogle Readerに登録していたのですが、これだと1 Tweetごとに別のエントリになってしまって、見にくいです。そこで、1日分の検索結果をまとめて1エントリにするAtomフィードを作りました。
実験的に作ったもので、配信を停止する場合があります。
[web][android] パスワードの代わりにAndroid携帯で認証するサイトのデモを作った
Yuyake - ブラウザ上でRubyでWebアプリ開発
色々未完成なのですが、放置気味だったのでとりあえず現状を公開することにしました。
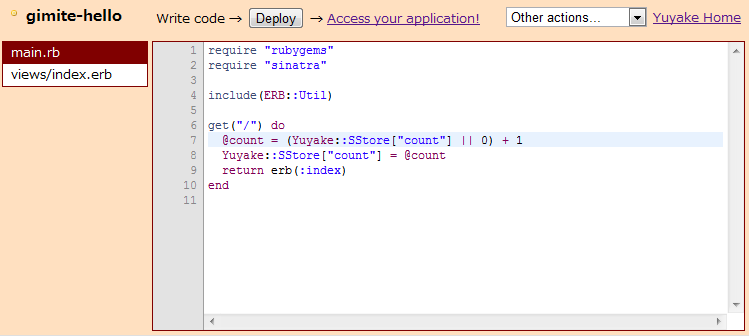
ブラウザ上でRubyでWebアプリを開発してそのまま実行できる、というものです。フレームワークはSinatraのみをサポートしてます。利用にはGoogleアカウント*1が必要です。
おことわり
実験的なサービスなので、突然落ちたり、サービス終了したり、データが消えたりする可能性があります。また、Yuyake上の全アプリケーションがAppEngineの無料クオータを共有することになるので、誰かが使いすぎるとサービス全体が落ちます :) まあ落ちてもいいのですが、わざと負荷をかけないようにしてください。
そんな感じでいまいち実用的ではないのですが、AppEngineで動くので、自分のアカウントで自分専用のやつを立ち上げることができます(ソースがあれば。近日公開予定)。その方法なら、使い物になるかもしれません。
利用可能なRubyの機能
FileとかSocketとか以外のRubyの組み込みクラス/標準ライブラリは使えるはずですが、サンドボックスのせいでところどころ動きません。データベースは現状使えませんが、Yuyake::SStore, Yuyake::AStoreというkey/valueストアが使えます。自動生成されるソースのコメント参照。
実装
Cloud9 IDE(これはnode.js用)のRuby版(&しょぼい版)みたいな感じです。Herokuが昔Railsで似たようなことをやっていた気がするのですが、今見るとローカルで書いてアップロードする方法しか見当たらない…。
実装はAppEngine+JRubyです。*2ユーザのコードはjavasandというJRubyのサンドボックスの中に入れて実行しています。
エディタの部分はCloud9 IDEのエディタ部分が単独で公開されているので、それを使っています。各種言語のシンタックスハイライトとかオートインデントとかしてくれて、いい感じです。
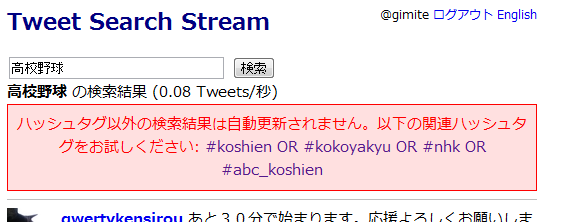
Tweet Search Streamが日本語ハッシュタグに対応
Tweet Search Streamを日本語ハッシュタグに対応させました。
例: #名言の文末を過去形にすると深みが増す - Tweet Search Stream
バリデーションを弱めればいいだけかと思ったら、
ので意外と面倒くさいことに。なんかバグがあるかもしれません。特にTweet中のオートリンクはそもそも仕様がよく分からないのでテキトーです。
# 日本語は単語間にスペースを入れる必要がないので、やたら長い(けど可読な)ハッシュタグが作れるんですね…。
[tss][websocket][js] web-socket-jsとTweet Search Streamのスライド
すっかり忘れていたのですが、しばらく前に社内でweb-socket-jsとTweet Search Streamについて発表する機会があったので、そのスライドを置いておきます。
内容的にはこのブログに書き散らしたことの詰め合わせみたいな感じだし、文字ばっかりだし、なんか英語だし、あまり面白くはないと思いますが…。
Fiberを使ってem-http-requestとかを同期的に呼び出す
EventMachineの関数(em-http-requestとか)を多用すると、コールバックだらけになって訳が分からなくなるのが欠点です。
Ruby 1.9のFiberを使うと、em-http-requestみたいな非同期関数を同期的に呼ぶことができます。em-synchronyというライブラリがそのようなラッパを提供してるのを見つけました。
require "em-synchrony" require "em-synchrony/em-http" p EM::HttpRequest.new("http://www.google.com").get.response p EM::HttpRequest.new("http://www.yahoo.com").get.response
こうするとhttp://www.google.comとhttp://www.yahoo.comを順にロードします(ロード中もちゃんとEventMachineが動きます)。これはFiberの中で実行する必要があります。方法としては、EM.synchronyを使う方法:
EM.synchrony do p EM::HttpRequest.new("http://www.google.com").get.response p EM::HttpRequest.new("http://www.yahoo.com").get.response end
と、自分でFiberを作る方法:
EM.run do ... Fiber.new { p EM::HttpRequest.new("http://www.google.com").get.response p EM::HttpRequest.new("http://www.yahoo.com").get.response }.resume ... end
があります。Sinatraで使う場合はrack-fiber_poolというのを使うと、リクエスト処理全体をFiberで囲ってくれるようです。
require "sinatra" require "em-synchrony" require "em-synchrony/em-http" require "rack/fiber_pool" use(Rack::FiberPool) get("/") do res1 = EM::HttpRequest.new("http://www.google.com").get.response res2 = EM::HttpRequest.new("http://www.yahoo.com").get.response res1 + res2 end
async_sinatraを使うのと同じことが、もっと楽に書けるわけですね。sinatra-synchronyというのもあるようですが、こっちはちゃんと見てないのでよくわかりません…。
ちなみに上のような例では(よく分からない例ですが)同時並行でロードするとベターなわけですが、そういう時のためにFiberを使って同時並行で実行するeachを作ってみました。
require "em-synchrony" require "em-synchrony/em-http" require "em-fiber-utils" EM.synchrony do urls = ["http://www.google.com", "http://www.yahoo.com"] EM::FiberUtils.concurrent_each(urls) do |url| # ここが同時並行で実行される。 p EM::HttpRequest.new(url).get.response end # 両方終わるとここに来る。 end